
Jest piątkowy wieczór, rozsiadasz się wygodnie na kanapie, odpalasz mecz. Dzwoni telefon z firmy… i już wiesz, że to nie będzie lekki weekend.
Zostaliście zaszyfrowani. Dostajecie notatkę o okupie. Co robić? Pojawia się panika, stres, presja. Potem pierwsze próby identyfikacji zagrożenia i łatania środowiska. W końcu trzeba odtworzyć się z backupu. No właśnie - czy macie jeszcze z czego się odtworzyć? Czy zdążycie zrobić to, zanim firma poniesie katastrofalne straty?
Ten scenariusz to nie fikcja. Z raportu CERT z 2025 roku wynika, że był rzeczywistością blisko 180 polskich firm każdej wielkości. Jak uniknąć takiego koszmaru? Wbrew pozorom to nie jest pytanie wyłącznie dla adminów - jest również odpowiedzialnością Biznesu. W tym przypadku świat techniczny i biznesowy są bowiem nierozerwalnie ze sobą połączone.
W tym artykule przyjrzymy się współczesnym zagrożeniom w kontekście kopii zapasowych, budowaniu strategii ciągłości działania i podstawach bezpiecznej architektury systemu backupu.
Dlaczego backup to dziś zupełnie inne wyzwanie niż jeszcze 10 lat temu?
Dekadę temu backup rozumieliśmy dosyć wąsko: po prostu jako kopię na wszelki wypadek - awarię sprzętu czy błąd użytkownika. Często był po prostu dodatkiem do obowiązków adminów, nie rozpatrywany jakoś szczególnie w kontekście całej firmy. Dziś takie podejście jest dalece niewystarczające. Obecnie powinniśmy już myśleć nie tyle o samym backupie, a o kompleksowej ochronie danych, będącej elementem strategii działania naszej organizacji. Właściwie co takiego zmieniło się w ciągu ostatnich 10-15 lat, że dawne podejście już się zdezaktualizowało?
Regulacje: ochrona danych nie jest już tylko sprawą IT
Wprowadzone w 2018 roku RODO było w pewnym sensie rewolucją w myśleniu o danych i ich zabezpieczaniu na różnych poziomach. Wcześniej atak hakerski i wyprowadzenie danych poza firmę oczywiście mogło być dotkliwe, jednak obecnie wiąże się nie tylko z przestojem, ale również z konsekwencjami prawnymi i wynikającymi z nich potencjalnymi karami finansowymi. Cyberprzestępcy doskonale o tym wiedzą, dlatego coraz większą popularność zyskują ataki typu double extortion, czyli podwójne wymuszenie. Polegają one na zaszyfrowaniu plików i żądaniu okupu w zamian nie tylko za ich odzyskanie, ale również brak upublicznienia. Wtedy nawet backupy nie załatwiają sprawy i sytuacja naraża firmę na daleko idące konsekwencje prawne, reputacyjne i finansowe.
Dyrektywa NIS2 jest kolejnym istotnym aspektem, który nakłada na firmy - a właściwie na zarządy - odpowiedzialność za bezpieczeństwo IT. Mimo że nie ma tam zbyt wielu konkretnych informacji na temat backupów, to przede wszystkim reguluje ich postrzeganie. Nie są one już tylko elementem dobrych praktyk, a częścią polityki ciągłości działania. Skutkuje też koniecznością posiadania odpowiednich procedur i polityk, ponieważ w razie incydentu albo kontroli będą one podlegały ocenie. Niespełnienie wymogów może zaś wiązać się z dotkliwymi karami finansowymi. W przypadku podmiotów kluczowych mogą one sięgać do 10 mln EUR lub 2% globalnego rocznego obrotu, natomiast dla podmiotów ważnych do 7 mln EUR lub 1,4% obrotu. Ostateczna wysokość kary zależy od kategorii podmiotu i charakteru naruszenia.
Ransomware jako usługa i sztuczna inteligencja
Dekadę temu ataki ransomware przygotowywane i wykonywane były głównie przez samych programistów - a przynajmniej ludzi o rozległych kwalifikacjach ze świata IT. Dziś poprzeczka, jaka potrzebna jest do wykonania skutecznych ataków drastycznie się obniżyła. Są ku temu dwa główne powody - komercjalizacja ataków ransomware i dostępność narzędzi AI.
Ataki ransomware stały się tak skutecznym narzędziem do pozyskiwania ogromnych pieniędzy, że dawno już przestały być domeną jedynie grup hakerskich czy nerdów znajdujących się po “złej stronie mocy”. Dziś Ransomware-as-a-Service (RaaS) jest modelem biznesowym (nielegalnym oczywiście) pozwalającym również mniej technicznym grupom załapać się na swój kawałek tortu nawet mimo braku kwalifikacji. Grupy świadczące takie usługi udostępniają wszystko, co potrzebne jest do wykonania udanego ataku: infrastrukturę, aplikacje, procedury a nawet działy “wsparcia” czy negocjatorów.
Z drugiej strony pojawiają się modele sztucznej inteligencji. Lata temu tzw. script kiddies, czyli ludzie aspirujący do miana “hakerów”, ale bez odpowiednich umiejętności, mieli do dyspozycji oczywiście jakieś gotowe narzędzia z Internetu lub darknetu, jednak ich szkodliwość była najczęściej znikoma, bo po prostu nie rozumieli co robią. Teraz ten deficyt technologiczny się zaciera, ponieważ wystarczy kilka trafnych promptów, aby AI pomogło zrozumieć działanie narzędzi, napisało skrypty, przeanalizowało błędy.
Efekt jest taki, że osoby z niewielką wiedzą techniczną są dziś w stanie robić rzeczy, które kilka lat temu wymagały znacznych kompetencji. W tym momencie warto zastanowić się, jakie możliwości daje sztuczna inteligencja w rękach kogoś, kto naprawdę wie co robi.
Rosnące koszty przestoju i skokowy wzrost zależności od IT
Nie będzie to nic odkrywczego, ale obecnie cały świat jest przesiąknięty zależnościami od Internetu i technologii. Jeśli w 2010 roku firma, sklep czy szpital mógł przez kilka godzin czy nawet dni działać “na kartce papieru”, to dziś już nie może. Niby każdy o tym wie, jednak w istocie wielu z nas może nie być do końca świadomych konsekwencji przestojów.
Koszty przerw w działaniu rosną, a potwierdzają to badania, takie jak raport Ponemon Institute z 2016 roku, który wskazuje, że średni koszt przestoju na każdą minutę wynosił 5617 USD w 2010 roku, 7908 USD w 2013 roku oraz 8851 USD w 2016 roku. Bardziej aktualne badania EMA Research wskazują z kolei na wzrost średniego kosztu przestoju z 12 900 USD w 2022 roku do ponad 14 000 USD w 2024.
| Rok | Koszt przestoju na minutę | Źródło |
|---|---|---|
| 2010 | 5617 USD | Ponemon Institute |
| 2013 | 7908 USD | Ponemon Institute |
| 2016 | 8851 USD | Ponemon Institute |
| 2022 | 12 900 USD | EMA Research |
| 2024 | 14 056 USD | EMA Research |
Oczywiście trudno porównywać do siebie tylko średnie kosztów z różnych badań, ponieważ mogą stosować różne metodologie i grupy firm, jednak trend wzrostowy jest wyraźny.
Rozproszenie, skala i odpowiedzialność za dane w chmurze i SaaS
W ciągu ostatnich dwóch dekad zwiększył się udział SaaS (Software-as-a-Service) w stosunku do rozwiązań on-premise. Z tego względu dane, których swoją drogą jest coraz więcej, ulegają znacznemu rozproszeniu - nie znajdują się już tylko na firmowych serwerach i komputerach, a również w chmurze i gdzieś w infrastrukturach usługodawców. Wielu ludzi niesłusznie zakłada, że nie musi dodatkowo zabezpieczać tych danych, bo należy to do obowiązków dostawców, tymczasem w wielu przypadkach odpowiedzialność za zrobienie backupów nadal pozostaje po stronie klienta. Poza tym nawet takim “niezniszczalnym” z założenia usługom jak Google Cloud zdarzyło się omyłkowo stracić dane klienta przez usunięcie całej subskrypcji. Funduszowi wartemu 135 miliardów dolarów udało się przetrwać wyłącznie dlatego, że miał dodatkowe backupy oparte na Commvaulcie poza ekosystemem Google.
Od backupu do ciągłości działania - kluczowe pojęcia i wskaźniki
No dobrze, wiemy co się zmieniło w ostatnich latach - co dalej? Jak przygotować siebie i naszą organizację do współczesnych zagrożeń?
Zacząłbym od zadania sobie kilku kluczowych pytań: jakie procesy biznesowe obecne są w naszej firmie? Co się stanie, kiedy jeden z nich - na przykład sprzedaż towarów - zostanie zachwiany? Ile będzie kosztować kilkugodzinny albo kilkudniowy przestój w świadczeniu usługi? Idąc dalej - co stanie się, kiedy jedna z aplikacji przestanie działać? Czy przypadkiem od jej działania nie zależy również dostępność innego systemu? Jaki maksymalny czas trwania awarii jest akceptowalny z punktu widzenia działania naszej firmy, a jaki spowoduje, że zwyczajnie już się nie podniesie?
Aby móc odpowiedzieć na te i wiele innych pytań, konieczne jest przeprowadzenie tzw. analizy BIA (Business Impact Analysis). Jest to proces identyfikacji ryzyk i oceny skutków potencjalnych zdarzeń zaburzających funkcjonowanie organizacji. Efektem takiej analizy będą dane, które następnie możemy wykorzystać w Planie Ciągłości Działania (BCP) i Planie Odtworzenia po Awarii (DRP).
Plan Ciągłości Działania (Business Continuity Plan) to dokument lub zbiór procedur określających jak firma będzie działać w przypadku kryzysów i zakłóceń. Dotyczy całości organizacji - obejmuje m.in. procesy biznesowe, role pracowników, alternatywne sposoby działania, schematy komunikacji awaryjnej. Plan BCP powinien być odpowiedzią na pytanie: jak działa firma w trakcie przywracania jej normalnego funkcjonowania. Nie skupia się więc jedynie na IT - może na przykład zawierać opis działania w przypadku awarii prądu dla jednego z działów, który będzie polegać na ręcznym wypisywaniu numerów zamówień na kartkach do czasu rozwiązania problemu.
Disaster Recovery Plan (DRP) jest zaś szczegółowym zbiorem zasad, procedur i polityk z zakresu IT opisujących odtworzenie infrastruktury i danych. Skupia się na technicznych aspektach przywracania działania systemów, na przykład przełączenia na zapasową serwerownię, odtworzeniu z backupu czy odbudowy konfiguracji serwera. W kontekście DRP najczęściej pojawiają się dwa kluczowe parametry:
- RTO (Recovery Time Objective) - czas, w jakim system powinien zostać przywrócony do działania
- RPO (Recovery Point Objective) - maksymalna ilość danych (określona w czasie), jaką można utracić. Mówiąc w uproszczeniu jest to oczekiwana częstotliwość backupów.
Dodatkowo możemy się spotkać z dodatkowymi wskaźnikami:
- MTD (Maximum Tolerable Downtime) - maksymalny czas, przez jaki firma jest w stanie funkcjonować bez danego systemu, zanim nastąpią katastrofalne skutki (po przekroczeniu tego czasu firma już nie będzie w stanie się podnieść).
- WRT (Work Recovery Time) - czas potrzebny na weryfikację systemów oraz danych i wznowienie działalności. Mówiąc inaczej, jest to czas na ostateczne “ogarnięcie” systemów już po odtworzeniu systemów, tak aby Biznes znowu mógł działać.
Gdyby zaprezentować wskaźniki na linii czasu, prezentowałyby się tak:
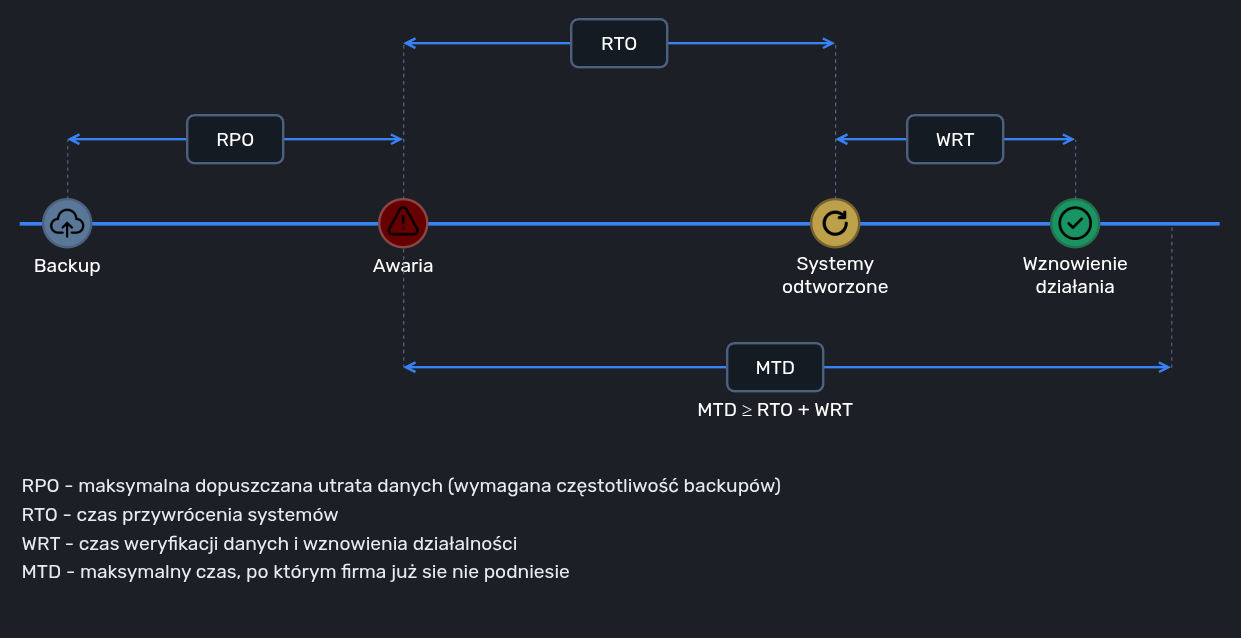
Chciałbym zaznaczyć, że wszystkie powyższe wskaźniki to dane oczekiwane, czyli zaakceptowane przez Biznes, a nie czasy, jakie wyszły nam w teście. Zadaniem testów jest bowiem sprawdzenie, czy jesteśmy w stanie spełnić te warunki. Jeśli nie, trzeba zidentyfikować, co możemy poprawić (infrastrukturę, systemy, procedury) i dążyć do takiego stanu, w którym osiągniemy te cele.
Realizacja BCP w praktyce
Opiszę, jak to wygląda z mojego doświadczenia. Otóż spotykamy się z właścicielami biznesowymi danych aplikacji czy systemów i zbieramy o nich informacje. Następnie tłumaczymy, czym są te wszystkie wskaźniki i prosimy o wstępne ich określenie (głównie RTO i RPO). Biznes zazwyczaj odpowiada wtedy coś w stylu, że nie mogą stracić żadnych danych i jak system nie będzie dostępny godzinę, to będzie tragedia i wszyscy umrzemy. No cóż, każdy właściciel myśli, że jego system jest najważniejszy. Wtedy najczęściej trzeba wyjaśnić, że dotyczy to naprawdę sytuacji awaryjnych, że często są inne - bardziej krytyczne systemy i niech jeszcze raz zastanowią się, czy na pewno ta niedostępność będzie tak dramatyczna w skutkach. Przede wszystkim niech zaś podejdą do tego empirycznie i spróbują określić, jakie będą finansowe skutki dla każdej godziny czy dni przestoju, szczególnie jeśli mówimy np. o aplikacjach sprzedażowych czy CRM.
Wtedy często okazuje się, że jak tak przemyślą sprawę, to ta aplikacja jednak nie jest taka krytyczna i poradzą sobie nawet przez kilka dni. Oczywiście mogą też przystać przy swoim - tak czy owak, jakieś parametry zostają ustalone i zapisane. Następnie my (admini) sprawdzamy, czy jesteśmy w stanie technicznie spełnić te wymagania. Czasem wiadomo to od razu (np. nie mamy wdrożonej replikacji, więc nie zrobimy RPO 1 min), czasem trzeba zrobić testy i przekonać się, co jesteśmy w stanie na obecnym etapie osiągnąć. Jeśli testy potwierdzają spełnienie założonych parametrów - można otwierać szampana. Jeśli nie - analizujemy co możemy zrobić, aby się to udało. Może trzeba coś inaczej skonfigurować, a może trzeba kupić sprzęt, software, licencje?
Z taką analizą wracamy do Biznesu: możemy zrobić to i to, aby spełnić wasze wymagania, ale to będzie kosztowało tyle i tyle. Teraz są 3 opcje:
- Biznes załatwia kasę na nasze zabawki, my to implementujemy i wszystko się zgadza,
- Biznes nie daje kasy, (np. bo koszty implementacji znacznie przewyższają potencjalne straty w wyniku przestoju) i rewiduje swoje parametry redukując je do realistycznych założeń, które jesteśmy w stanie technicznie wyegzekwować,
- Biznes nie daje kasy i nie zgadza się na poluźnienie parametrów - sytuacja patowa, ale ostatecznie to oni biorą na siebie ryzyko - w końcu nie wyczarujemy im np. nowego sprzętu bez pieniędzy.
Wiesz już, jak z grubsza wygląda proces analizy BCP. Ale właściwie na jakie problemy się przygotowujemy?
Krajobraz zagrożeń w kontekście kopii zapasowych
Być może od razu pomyślałeś o ransomware. Nie bez przyczyny - słyszy się o tym zewsząd i najbardziej działa na wyobraźnię. Ale czy to najpoważniejsze zagrożenie?
Błąd ludzki i awarie sprzętu są groźniejsze niż myślisz
Ransomware jest jednym z najpoważniejszych w skutkach powodów przestojów, jednak nie zawsze najczęstszym. Wg badania Unitrends z 2025 roku statystycznie najczęstszą przyczyną utraty danych jest awaria sprzętu (22%), awaria usługodawcy (19%) a potem błąd ludzki i właśnie ransomware (po 18%). Nie sugerowałbym jednak zbytnio przywiązywać się do procentów, bo rozstrzał w badaniach jest dość spory, wniosek jest jednak inny - nie należy lekceważyć żadnej z potencjalnych przyczyn. Błąd admina może być równie katastrofalny w skutkach, co atak hakerski. Najbardziej znanym tego przykładem był incydent Gitlaba z 2017 roku, gdzie przez przypadkowe “rm -rf” serwis był niedostępny przez wiele godzin i stracił część danych. Jest to też przykład innego zdradliwego przeświadczenia, czyli “mamy backup, więc jesteśmy bezpieczni”.
Nietestowany backup to w rzeczywistości brak backupu
Współczesne systemy kopii zapasowych mają pełno funkcjonalności sprawdzających poprawność backupu - porównują sumy kontrolne, robią cykliczne skany czy alertują o korupcji systemu plików. Nie możemy jednak polegać wyłącznie na automatycznych mechanizmach. Często okazuje się, że problem z backupami nie dotyczy nawet stricte uszkodzenia danych, tylko kwestii “pobocznych”.
Przykład z życia: bazy SQL Server backupowane bez SystemDB. W razie poważnej awarii oprócz samego odtwarzania czeka wtedy adminów mnóstwo dodatkowej, ręcznej roboty. Inny przypadek: robiliśmy testy odtwarzania maszyn wirtualnych pewnego środowiska i okazało się, że mają one problem z podpięciem zewnętrznego dysku i konieczna jest manualna interwencja. Okazało się, że nie był to wcale problem backupu - te maszyny nigdy nie podpinały zasobów poprawnie po uruchomieniu, tyle że przez długie miesiące nikt ich nie restartował, więc i problem nie miał okazji zaistnieć. Test wykazał więc zupełnie poboczny temat, ale właśnie w tym jego wartość. Bez niego mógł wystąpić w najgorszym możliwym momencie, a tak został zidentyfikowany w całkowicie kontrolowanych warunkach.
Kolejna rzecz, która może uśpić naszą czujność to nierealistyczne czasy odtwarzania. Mianowicie w znacznej większości przypadków opisywanych w przytoczonych wcześniej badaniach realny czas odzyskiwania był dużo większy niż ten z założeń. Może to oznaczać kilka rzeczy:
- administratorzy używają zbyt optymistycznych lub uproszczonych założeń testów, przez co ich wyniki na papierze wydają się dobre, ale nie przeżywają zderzenia z rzeczywistością,
- wyniki testów wskazują na problemy, ale brak jest środków lub inicjatywy, aby je naprawić,
- część adminów po prostu nie robi testów,
- admini napotykają się na niespodziewane problemy z infrastrukturą backupu podczas awarii czy ataków, co może oznaczać jej niedostateczne zabezpieczenie lub… niewystarczająco przetestowane procedury awaryjne - czyli wracamy do punktu wyjścia.
Uzyskiwanie realnych czasów odzyskiwania i porównywanie ich z założonymi parametrami (np. RTO) jest kluczowe i musi być regularnym procesem, który w razie potrzeby powinien być udoskonalany z każdą iteracją testów.
Masz dobrze zabezpieczony backup. Jesteś pewien?
System backupu to dosłownie pierwsza rzecz, do jakiej atakujący chcą uzyskać dostęp. Zdobycie nad nim kontroli w zasadzie sprawia, że jest już “po zawodach”. Inną opcją jest przejęcie infrastruktury, na której ten system stoi - na przykład serwerów lub macierzy. Każda z tych ewentualności może być dramatyczna w skutkach. Dlatego system backupu i wszystko co z nim związane musi być jak twierdza - odseparowana, zabezpieczona i aktywnie chroniona. Nie jest jednak łatwo być ekspertem od wszystkiego i każdy admin może pominąć coś, co może być istotne z punktu widzenia bezpieczeństwa infrastruktury backupu. Dlatego tak ważne są solidne audyty bezpieczeństwa. Podkreślam - solidne, bo nie chodzi mi o takie “na sztukę”, aby tylko spełnić jakieś regulacje, a o kompleksowe przeglądy robione przez ludzi, którzy się na tym znają.
Kiedy w ramach pewnego projektu miał odbyć się taki audyt, oczywiście zdawałem sobie sprawę z niektórych niedociągnięć, które mogą być wypunktowane. Niektóre z nich nie były zależne ode mnie. Nie spodziewałem się jednak właściwie żadnych krytycznych problemów - w końcu zawsze podążałem za dobrymi praktykami, uczestniczyłem w szkoleniach i konferencjach, byłem na bieżąco, system był aktywnie zarządzany.
Jakież było moje zdziwienie, kiedy przeczytałem raport. Liczba rzeczy, o których zwyczajnie nie pomyślałem bardzo mnie zaskoczyła. Szczególnie, że wiele z nich wydało mi się oczywiste, ale jednak dopiero po wytknięciu przez kogoś z zewnątrz. Dlatego uważam, że audyty to świetna rzecz - nie dość, że zwiększamy bezpieczeństwo, to jeszcze wiele można się przy tym nauczyć.
Zasada 3-2-1 jako punkt wyjścia do architektury backupu
Wielu z was słyszało zapewne o często powtarzanej w kontekście backupu zasadzie 3-2-1. Zakłada ona:
- 3 egzemplarze danych
- 2 różne rodzaje nośników
- 1 kopia w innej lokalizacji
Co ciekawe, chociaż zasada ta brzmi jak korporacyjny standard, swoje źródło ma w książce Digital Asset Management for Photographers autorstwa fotografa Petera Krogha wydanej w 2005 roku. Powstała więc jako sposób na ochronę zdjęć, jednak przez jej uniwersalność szybko weszła do świata IT. Przyjrzymy się jej bliżej.
3 egzemplarze danych
Jest tutaj istotny niuans językowy. W polskich źródłach często używane jest nieco mylące określenie 3 kopii, które będąc dosłownym tłumaczeniem z języka angielskiego może sugerować 3 kopie zapasowe i oryginał danych. Pierwotna zasada mówi natomiast o danych produkcyjnych i dwóch kopiach (czyli łącznie trzech egzemplarzach danych). Musimy jednak pamiętać, że zasada ta była pisana dla fotografów, a nie administratorów IT, dlatego w wielu przypadkach posiadanie nie dwóch, a trzech kopii zapasowych będzie nie tylko preferowane, ale wręcz konieczne. Liczba kopii zapasowych powinna wynikać ze świadomej decyzji opartej o analizę ryzyka.
2 różne rodzaje nośników
Autor książki zwracał uwagę, że różne nośniki psują się w różny sposób. Należy więc unikać tych samych nośników, aby w efekcie nie doświadczyć wspólnej przyczyny awarii. Należy spojrzeć na tę zasadę w nieco szerszym kontekście - chodzi tak naprawdę o maksymalną niezależność technologii między kopiami. Dlatego choć na przykład posiadanie kopii zapasowych na dwóch serwerach, z których jeden ma dyski SSD, a drugi HDD, jest w pewnym stopniu jakimś rozgraniczeniem technologii (SSD trapią inne bolączki niż HDD, więc jest duża szansa, że nie padną w tym samym momencie), to jednak nadal jest bardzo dużo podobieństw (sieć, systemy operacyjne, sposób zapisu). Kiedy więc pojawi się wadliwa aktualizacja na systemie, który jest taki sam na obydwu urządzeniach, efekt będzie ten sam (niedostępność). Rozgraniczenie powinno być mocniejsze, np.:
- macierz dyskowa + chmura publiczna
- NAS + taśmy LTO
- storage blokowy + storage obiektowy.
1 kopia w innej lokalizacji
Zasada wydaje się dosyć oczywista i naturalna. Jedna z kopii zapasowych musi być w innym miejscu niż kopia pierwsza / produkcja. Ale i tutaj mogą pojawić się różne interpretacje. Macierze dyskowe w dwóch serwerowniach w tym samym budynku, ale na innych piętrach tej zasady raczej nie będą spełniać. No bo co w przypadku pożaru budynku lub awarii prądu?
Dlatego lokalizacje muszą być również odseparowane geograficznie. Jak bardzo? Chciałoby się odpowiedzieć: to zależy - głównie od wyników naszej analizy BIA i ryzyk, jakie tam zdefiniowaliśmy. Na ich podstawie powinniśmy zdecydować o optymalnej lokalizacji drugiego / zapasowego datacenter. Wiele firm ma swoje centra danych w jednym mieście i uważa to za wystarczającą separację. Należy mieć jednak na uwadze, że takie rozwiązanie, choć niewątpliwie mające swoje zalety (np. możliwość doprowadzenia dedykowanych połączeń sieciowych czy niskie opóźnienia - bardzo istotne szczególnie w niektórych systemach replikacji) mogą stać się problematyczne w niektórych scenariuszach. Wystarczy wspomnieć choćby o blackoucie. Może wydawać się to mało prawdopodobne, ale nie trzeba daleko szukać: w Niemczech na początku 2026 roku w celowym sabotażu uszkodzono linie energetyczne, skutkiem czego 45 tys. gospodarstw pozbawiono prądu na kilka dni. Nawet pożar Mostu Łazienkowskiego w 2015 roku skutkujący uszkodzeniem połączeń światłowodowych różnych operatorów spowodował problemy z Internetem w wielu miejscach Warszawy. Po rosyjskiej agresji na Ukrainie również scenariusz ataku rakietowego na miasto przestał być już tylko science-fiction.
Dlatego uważam, że minimum jeśli chodzi o separacje lokalizacji to dwa różne miasta. Innym dobrym rozwiązaniem może być skorzystanie z usług dostawców chmurowych i tym sposobem posiadanie swoich kopii właściwie w dowolnym miejscu na świecie. Zresztą infrastruktura oparta o chmurę ma jeszcze inne atuty, a związane są z obiektowością storage.
Niezmienność i integralność - rozszerzenie zasady 3-2-1
Weźmy bowiem klasyczną architekturę backupu - mamy albo jakiś serwer wypełniony dyskami, albo zasoby wystawione z macierzy. Możemy mieć bardzo dobrze skonfigurowany i zabezpieczony centralny serwer backupu, ale jeśli ktoś zdobędzie dostęp i wyeskaluje uprawnienia na hoście z fizycznym dostępem do danych - nic nas nie uratuje.
Sytuacja zmienia się na naszą korzyść, jeśli korzystamy z obiektowego storage - Azure lub czegokolwiek opartego na S3 (np. AWS, Oracle Cloud itp.). Przy odpowiedniej konfiguracji atakujący nie będzie w stanie usunąć, zaszyfrować czy zmniejszyć retencji backupów nawet w przypadku, gdyby miał dostęp admina w systemie backupu, roota na serwerze a nawet uprawnienia w samym panelu chmurowym! Dzieje się to dzięki regułom blokowania obiektów (object lock) i niezmienności (immutability) oraz samej naturze obiektowego storage, gdzie OS nie ma bezpośredniego dostępu do danych jak w przypadku storage blokowego, a komunikuje się po API. W tym kontekście warto przytoczyć raport At-bay z 2023 roku, z którego wynika, że architektura backupu chmurowego zapewnia najwyższe prawdopodobieństwo skutecznego przywrócenia danych - 80%, co jest ok. 1,5-krotnie lepszym wynikiem niż backup off-site (55%) i on-site (56%).
Chmura naturalnie ma swoje wady i nie jest oczywiście jedyną opcją na zapewnienie niezmienności. Równie skutecznym sposobem są taśmy LTO (niektórzy wieszczyli im rychły koniec, tymczasem nadal są w powszechnym użyciu i technologia jest rozwijana). Na rynku dostępnych jest również wiele urządzeń korzystających z S3, które możemy używać on-premise i nie oddawać danych publicznemu dostawcy. Ciekawą opcją są również takie rozwiązania, jak Veeam Hardened Repository, czyli sposób na utworzenie zabezpieczonego repozytorium praktycznie na dowolnym sprzęcie.
Wszystko to służy zapewnieniu niezmienności danych, co jest kluczowe dla naszych firm (nawet pod kątem regulacyjnym - NIS2 tego wymaga). Takie działanie jest też wypełnieniem zasad rozszeżonej zasady 3-2-1 - czyli 3-2-1-1-0. Do “normalnej” reguły zostały dodane:
- 1 - co najmniej jedna kopia immutable / air-gapped (fizycznie odizolowanej od sieci)
- 0 - zero błędów weryfikacji podczas testów odtworzeniowych lub mechanizmów sprawdzania backupów.
Podsumowanie
Współczesne zagrożenia, regulacje i skala zależności od IT sprawiają, że zadawanie sobie pytania “czy mamy backup” to za mało. O wiele bardziej aktualne byłoby: “czy będziemy w stanie odzyskać dane i wznowić działanie w założonym czasie, bez względu na skalę incydentu?” Niestety nie ma tutaj dróg na skróty, dlatego aby móc odpowiedzieć twierdząco, należy sumiennie zmierzyć się ze wszystkimi wspomnianymi zagadnieniami: analizą BIA, politykami BCP i DRP, zasadami niezmienności czy regularnym testowaniem kopii zapasowych.
Mam nadzieję, że po lekturze tego artykułu stało się dla Ciebie jasne, że backup to zarówno kwestia techniczna, jak i biznesowa i są to światy nierozłącznie ze sobą powiązane, a pozytywny efekt będzie możliwy wyłącznie dzięki dobrej współpracy obydwu tych stron.
Źródła
- Raport roczny 2025 z działalności CERT Polska
- Raport Cost of Data Center Outages 2016 - Ponemon Institute
- Raport IT outages: 2024 costs and containment - EMA
- Raport The State of Backup and Recovery Report 2025 - Unitrends
- Raport Backup Breakdown: How Data Recovery Impacts the Outcome of Cyber Attacks - At-bay
Komentarze